How to Connect Azure Synapse Analytics with Power App’s Common Data Service

Chandra

Azure Synapse uses Azure Data Lake Storage Gen2 as a data warehouse and a consistent data model that incorporates administration, monitoring, and metadata management sections. Data Lake Storage Gen2 makes Azure Storage the foundation for building enterprise data lakes on Azure. Designed from the start to service multiple petabytes of information while sustaining hundreds of gigabits of throughput, Data Lake Storage Gen2 allows you to manage massive amounts of data efficiently.
In the past, cloud-based analytics had to compromise in areas of performance, management, and security. Data Lake Storage Gen2 helps customers by addresses each of these aspects in the following ways:
- Performance: is optimized; we do not need to copy or transform data as a prerequisite for analysis. The hierarchical namespace greatly improves the performance of directory management operations, which improves overall job performance.
- Management is easier now; we can organize and manipulate files through directories and subdirectories.
- Security is enforceable because we can define POSIX permissions on directories or individual files.
- Cost effectiveness is made possible as Data Lake Storage Gen2 is built on top of the low-cost Azure Blob storage. Data Lake Storage Gen2 is very cost effective because it is built on top of the low-cost Azure Blob storage.
A key mechanism that allows Azure Data Lake Storage Gen2 to provide file system performance at object storage scale and prices is the addition of a hierarchical namespace. This allows the collection of objects/files within an account to be organized into a hierarchy of directories and nested subdirectories in the same way that the file system on our computer is organized. With a hierarchical namespace enabled, a storage account becomes capable of providing the scalability and cost-effectiveness of object storage, with file system semantics that are familiar to analytics engines and frameworks.
Also, Data Lake Storage bringing Common Data Models (CMD) to the platform will helpto reducethe gap between the Power PlatformandAzure Data Services.

Common Data Service (CDS)
Common Data Service is a data storage service. We can use CDS to store data in the form of tables, which is called as Entities. Common Data Service is a service that is used mainly in the Power Apps portal; however, it is accessible through other Power Platform services and Microsoft Dynamics. Data can be loaded into CDS entities through multiple ways, and it can be also extracted from there through different methods.
Behind the PowerApps platform, we have another feature, the Export to data lake service enables continuous replication of Common Data Service entity data to Azure Data Lake Gen 2 which can then be used to run analytics such as Power BI reporting, ML, Data Warehousing, and other downstream integration purposes.

Export to data lake is a Power Apps service that allows Common Data Service (CDS) customers to continuously push their data to ADLS in the CDM format. The greatest thing about this service is the ability to incrementally replicate the CUD operations in ADLS without having to run manual/scheduled triggers. Any data or metadata changes in CDS are automatically pushed to ADLS without any additional action. Read-only snapshots are created every hour in ADLS, allowing data analytics consumers to reliably consume the data.
Prerequisites:
- The storage account must be created in the same Azure AD tenant as your Power Apps tenant.
- The storage account must be created in the same region as the Power Apps environment that will host the applications.
To create a new link to the data lake and select which entities we want to export. As mentioned above, we will be asked to attach a storage account in the same location of the Power Apps tenant. We will also need to be the Owner of the storage account and the administrator of the CDS.
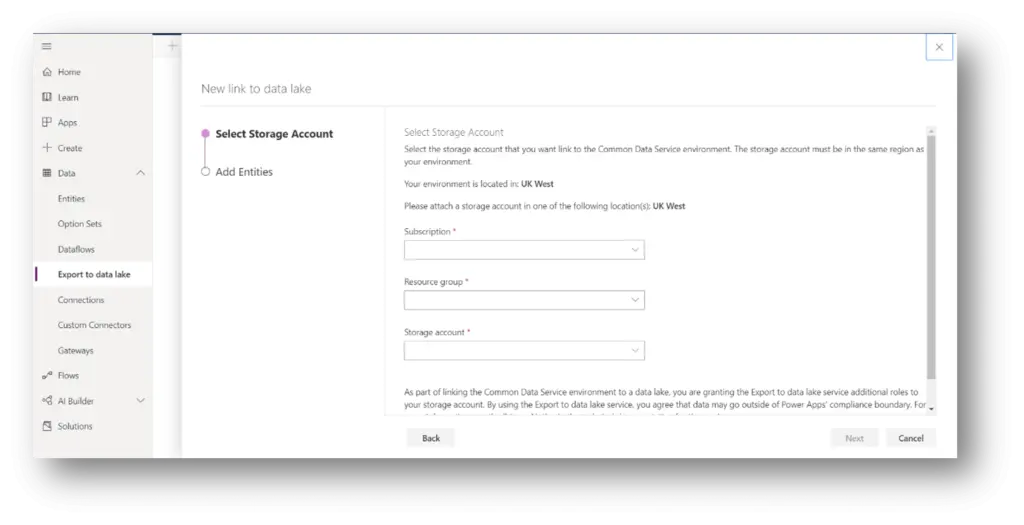
Provide storage account and their subscription and resource group details. And choose which entity you want to export to storage account.
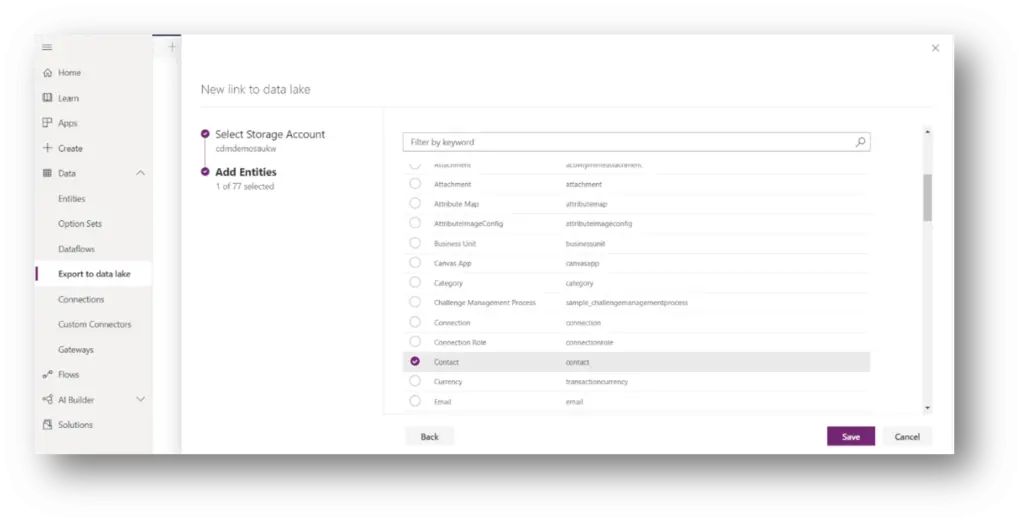
Once you save action, the CDS environment is linked to ADLS and the selected entities are replicated to the storage account.
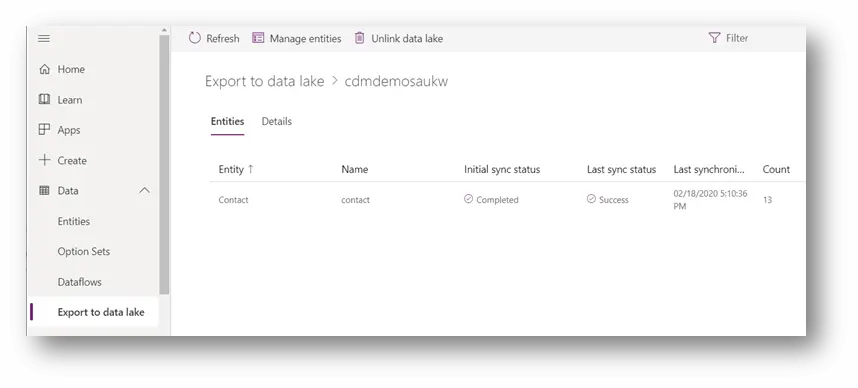
On the Power Apps portal, we will see the status (Initial sync and Last sync status), the last synchronized timestamp and the count of records for each selected entity.
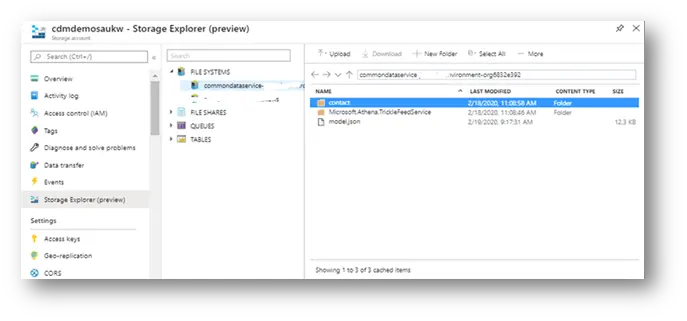
On the storage account, we will see a new container, the link we just created it named “commondataservice-*“. Within the container, we have a model.json file, a folder for the Trickle Feed Service and a folder for each selected entity.
Learn about the Common Data Model structure.
Once the Common data model synchronized with data lake storage gen2, Azure Synapse Services enable advanced analytics that let you maximize the business value of data stored in CDM folders in the data lake. Data engineers and data scientists can use Azure Databricks and Azure Data Factory dataflows to cleanse and reshape data, ensuring it is accurate and complete.
Select one or more files, which are available in entity folder, and then create a new SQL script or a spark notebook to see the content of the file(s). Spark pool is required to execute notebook.
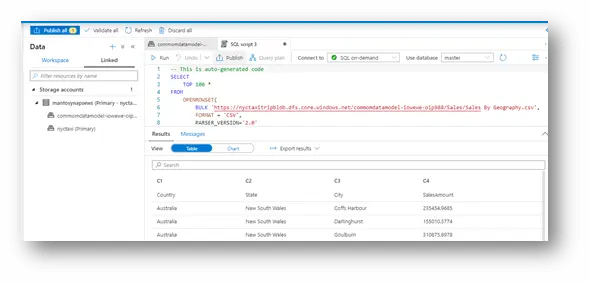
Querying data in ADLS Gen2 storage using T-SQL is made easy because of the OPENROWSET function with additional capabilities. The currently supported file types in ADLS Gen2 that SQL-on-demand can use are Parquet, CSV, and JSON. The data source is an Azure storage account, and it can be explicitly referenced in the OPENROWSET function or can be dynamically inferred from URL of the files that you want to read.
Note: Azure AD users can access any file on Azure storage if they haveStorage Blob Data Owner,Storage Blob Data Contributor, or Storage Blob Data Readerrole. Azure AD users do not need credentials to access storage.
Synapse providing bulk load option for data engineers to load data into provisioned data warehouse. Here I am demonstrating how to configure COPY Statement it is easier way than PolyBase mechanism.
Select one file, which are available in entity folder, and then create a new SQL script then choose Bulk load.
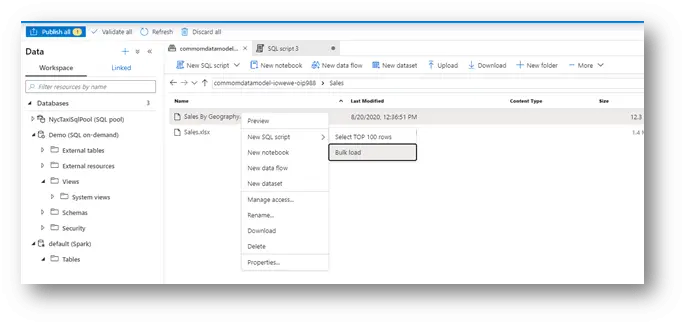
Changed FirstRow =1, using this property we can skip the header in file if it contains columns. I left remain same. Then click continue.
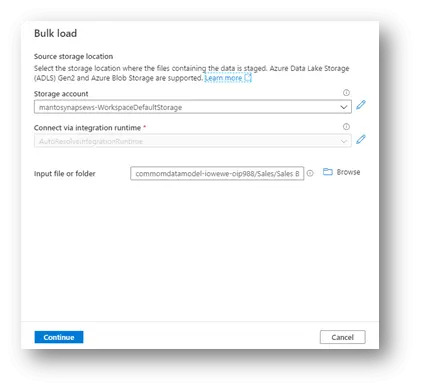
Then provide the required configuration information (Storage account, Integration Runtime and input file) in Bulk load window. Click continue.
Provide the right SQL pool and table name as target, SQL On-demand pool would not be list out in dropdown list. We chose the csv file to query from storage account, but it is not automatic schema inference. So, click Configure column mapping link, to provide mapping explicitly.
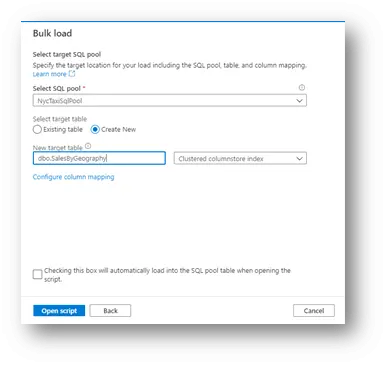
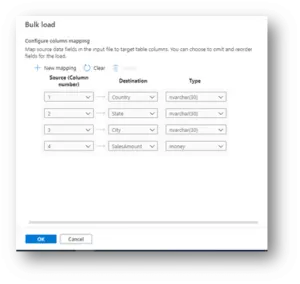
We need map the position of source columns to target columns. Then click Ok, enable check box to run automatically load once you click Open script.
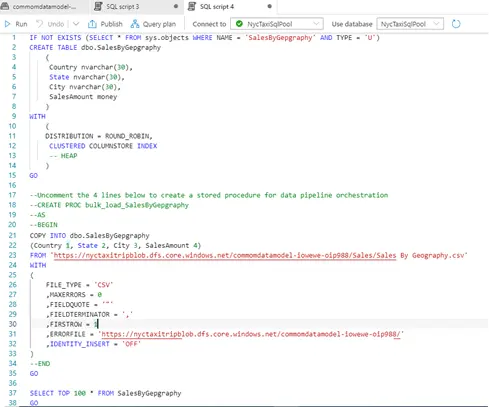
We could see final script here, verify then run the script.
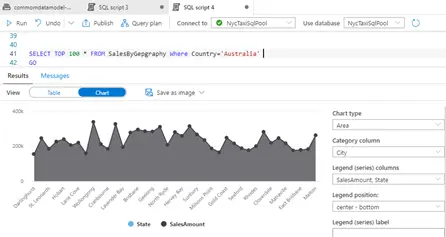
We can verify that is table created with bulk load script, we could see tabular and chart type results.
Conclusion
The common data model stores the data into Azure Data Lake Storage (ADLS) Gen2, with help of Export to data lake option from PowerApps and it is easy way, so that we do not want look into other integration options. We can leverage a new data integration option The COPY statement to query CDM data and load into Data warehouse. It is the most flexible and easy data loading technique for Synapse SQL.





