Feature Store for AI – Should one Build or Buy?

VirooPax

Machine learning needs data and context to enhance and refine its predictions. With complex and large volumes of data, AI Machine Learning (ML) models get a larger playground to develop precision. One problem that may hinder this learning process is the lack of quality data in the production environment. Access to historical data and related features can make AI/ML outcomes much more accurate & reliable.
Data scientists experience pain-points like concept drift, bias, locality, data quality and governance as their models degrade over time due to disparity in training vs production parameters. The model, feature, & data versions do tend to drift and give wrong predictions over the time regardless. Several firms do not deploy models with scalability & high data quality, and hence remain confined to sandboxes or within silos in an organization with no clearly defined process for the ML Ops lifecycle. If we want to relieve data scientists and engineers from such repetitive nightmares, we should consider a better MLOps approach with Feature store as a way to make AI projects fly.
Jim Dowling, CEO Logical Clocks, and the lead architect of the open-source Hopsworks AI platform compares such AI models to jellyfish — “its autonomic system makes it functional and useful, but it lacks a brain”. A unified platform consisting of models with access to latency access to enterprise data can really change the game. It can accelerate the learning process and evolve the brainless, jellyfish-AI into smart and intuitive ‘total recall’ AI. Such a unified and centralized platform that allows retrieval of key features’ databases for the purpose of learning and serving models, is known as a Feature Store.
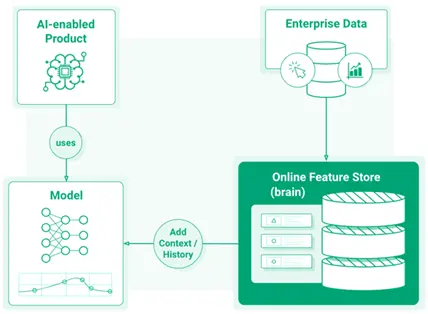
Source: Online feature store
In a separate conversation, Dowling explains how code nuances impact AI developers. “In order to serve models in production, you need to feed them with (often non-trivial) features. Those features are computed from input data, and the code that computes the features should be the same for both training and serving. You should not re-implement feature engineering code for serving as non-DRY feature engineering code increases the risk of subtle differences in the implementations that introduce difficult to track down bugs.”
What is a Feature Store?
The feature store in AI / ML is a feature computation and storage service that enables features to be registered, discovered, and used both as part of ML pipelines as well as by online applications for model inferencing. Feature Store is designed to store both large volumes of feature data and provide low latency access to features for online applications. They are typically implemented as a dual-database system: a low latency online feature store and a scale-out SQL database to store feature data for training and batch applications. The online feature store enables online applications to enrich feature vectors with near real-time feature data before performing inference requests. The offline feature store can store large volumes of feature data that is used to create train/test data for model development or by batch applications for model scoring.
To enable AI and ML products with actual and contextual data, a Feature Store should have three core attributes:
- Efficient access to the large volumes of historical features and low-latency access to the latest values of features
- Intuitive and ease of use for data scientists
- Discoverable features, which means they must be properly stored, versioned and organized.
Let’s consider the obvious question now, which is, ‘How does one deploy a Feature Store’? Well, there are atleast 2 options: if you are a large organization and deal with a specific data type, you could custom build a Feature Store, Or if you are a mid-sized/small firm managing a variety of use cases, you might want to consider buying one. But first, let’s see what the leading brands are doing since the last 3-4 years.
Feature Stores by Digital Natives
Volumes of data and variety of models are to be considered for digital natives who are ‘AI-first’ in their feature engineering approach. To organize these models and data, they’ve developed custom Feature Stores that have become leading examples for others. Among the pioneers, are big names like Michelangelo Palette – the first feature store (by Uber) that is heavily built around Spark/Scala with Hive (offline) and Cassandra (online) databases; FBLearner by Facebook; Databricks Feature Store – the first feature store co-designed with a data platform and MLOps framework; and Hopsworks – the first fully open-source Feature Store, based around Dataframes (Spark/Pandas), Hive (offline), and MySQL Cluster (online) databases.
Here’s a look at how some of the earliest tech giants are progressing on the AI and ML Feature Stores’ front: Vertex AI – the Google MLops Platform with a Feature Store, Amazon Feature Store, Survey Monkey – a feature store for AWS that has both an offline and an online database, and Spotify – a feature store for KubeFlow on GCP. Comcast has had two iterations of their Feature Store; Netflix uses shared feature encoder libraries in their MetaFlow platform; Overton is Apple’s platform for managing data and models for ML.; Galaxy is Pinterest’s incremental dataflow-based Feature Store on AWS; StreamSQL have built a Feature Store as a commercial product based on Apache Pulsar, Cassandra, and Redis; GoJek/Google released FEAST in early 2019.
Build vs. Buy
If you are at a stage where a Feature Store can address your everyday features data problems, you can:
- Custom build
- Invest in FEAST – a standalone Feature Store or go for Hopsworks Feature Store
- Leverage existing Databricks on Azure (or AWS) while harnessing MLFlow and the Feature store
Option 1: Custom build a Feature Store
Custom building a Feature Store requires being aware of key implications, complexities, and answers to a few critical questions.
- Time & Cost
- It could take anything from 6 months to a year to have a production ready store.
- There will be production cost, maintenance cost as well as upgradation cost in the future.
- Key Problem/s to Solve
- Figure out if you wish to use a Feature Store as a store or a library. If all you need is consistent feature engineering and serving features support, you can use it just as a library.
- If you want to reuse features across models, it will require creating training datasets as well as serving features. A few feature stores do provide a single datastore for both.
- You also need to be sure if you need data stores for both – offline (scalable SQL) and online (low latency feature serving) stores. Hopsworks, for example, has built a singular metadata layer for their file system, feature serving, and their scalable SQL. It makes it convenient to add extended metadata for describing features, their statistics, and tagging them.
- Complexities & Challenges
Developing a custom Feature Store requires careful selection and design to optimize costs. Right assessments and decisions can prevent budget overshooting, delay in delivery and hampering runtime performance. However, there are many other concerns and challenges that need to be taken into consideration.
Large organizations deal with billions of data records that need to be stored and updated from time to time to avoid loss of data in case of an unexpected system failure. Therefore, the Feature Stores must be able to handle the large volumes and support regular back up. Batch random reads add another layer of complexity. If you have a high request and prediction serving rate, the Feature Stores must be able to support such high (usually millions) of reads per second. Further, dealing with heterogeneous data requires setting up specific optimization features. Each type of data needs to be individually addressed for efficient storage and retrieval. Guaranteed low latency reads, flexibility with write and updates, and identifying benchmarking and performance metrics are other factors that add complexity to custom building a Feature Store.
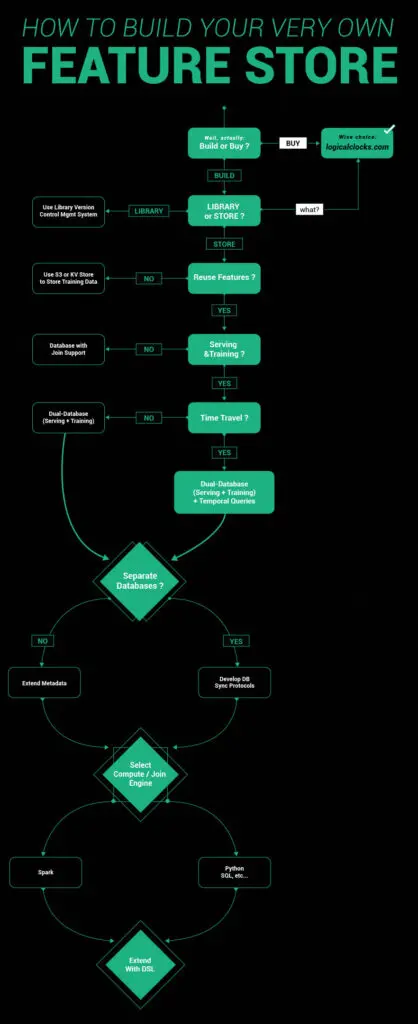
Source: How to Build Your Own Feature Store
Option 2: Buy a Feature Store
An organization could consider buying a Feature Store due to various strategic reasons as illustrated in the table below. Two popular options that are currently ruling the roost are FEAST and Hopworks. Hopsworks includes a feature store and many other features, such as model serving and notebooks. It is just one component of the larger Hopsworks data science platform. FEAST, on the other hand, is a standalone feature and much more specialized in storing and managing features. It can be easily integrated into any existing platform unlike Hopsworks, which makes more sense if you are already using their larger platform. There is also Databricks Feature Store that enables data teams to create new features, explore and reuse existing ones, publish features to low-latency online stores, build training data sets and retrieve feature values for batch inference.
So, how do you choose?
If you are thinking about a Feature Store, here are a few important points to consider and evaluate. First, how do you know if it is your business’ need at the current stage? Easy, while working on your AI project, have you ever lost track of the features in use, or duplicated your training code, or waited too long for ETL to finish reprocessing the same data? If not, you can do without a Feature Store for now. Organizations that are small or medium sized or are training only a handful of models or just testing the waters, need not consider investing in a Feature Store yet.
Mid-sized and big organizations that deal with humongous data, invest in AI and ML ventures, and frequently encounter features data issues like the ones mentioned above, should look at the store option. Building a custom Feature Store can unlock a host of benefits if you are a large business that can spread the cost of a proprietary system over many clients. If time and budget is not a constraint, and AI/ML based products are your competitive advantage, then you should build. However, most features data needs can be addressed by platforms like FEAST, Hopsworks and Databricks Feature Stores. They are smart and key-value based stores that support online and offline feature stores at the time when you need them.

Option 3: Use MLflow +with existing Databricks on Azure
There is another newer option that can solve and set things for you. Databricks on MS Azure is now going beyond feature factory to facilitating storage of features online application support and model serving, here is how.
MLflow is an open-source platform for managing the end-to-end machine learning lifecycle. It includes Feature Store and allows tracking and recording experiments, comparing results, managing, and deploying models, and makes ML codes reusable, reproducible and shareable. It also enables model registry and model serving. Azure Databricks provides a fully managed and hosted version of MLflow, which is integrated with enterprise security features, high availability, and other Azure Databricks workspace features.
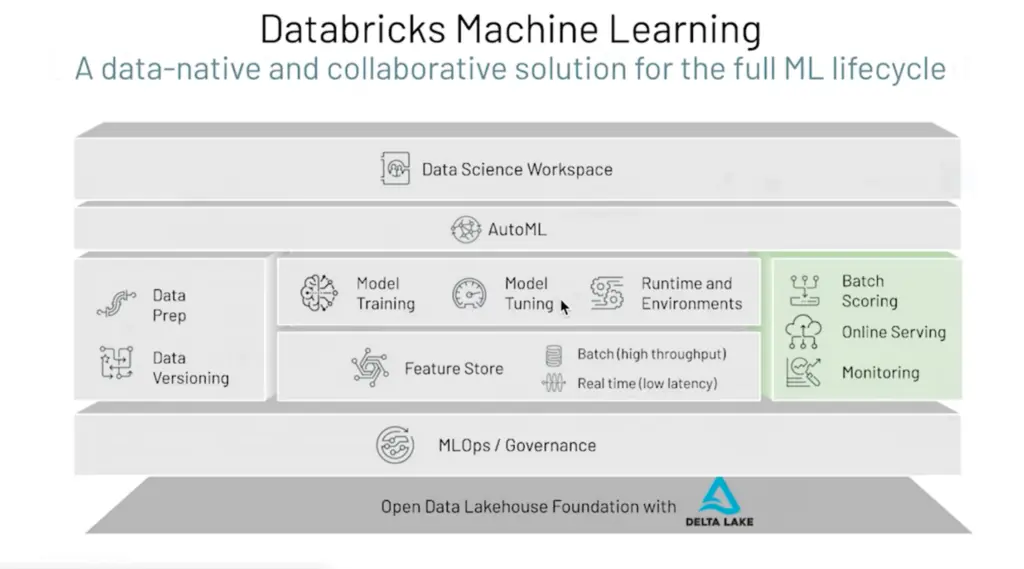
Source: Databricks Documentation
Feature Store on Databricks offers an integrated experience for tracking and securing machine learning model training runs and running machine learning projects. If you are new to it, you can quickstart with a demonstration of the basic MLflow tracking APIs. Briefly, MLflow Model Registry is a centralized model repository and provides chronological model lineage, model versioning, and stage transitions, just like Feature Store. Further, MLflow Model Serving allows you to host machine learning models from Model Registry as REST endpoints. These endpoints are updated automatically based on the availability of model versions and their stages.
When you enable model serving for a given registered model, Databricks automatically creates a unique cluster for the model and deploys all non-archived versions of the model on that cluster. Databricks restarts the cluster if an error occurs and terminates the cluster when you disable model serving for the model. Model serving automatically syncs with Model Registry and deploys any new registered model versions. Deployed model versions can be queried with a standard REST API request. Databricks authenticates requests to the model using its standard authentication.
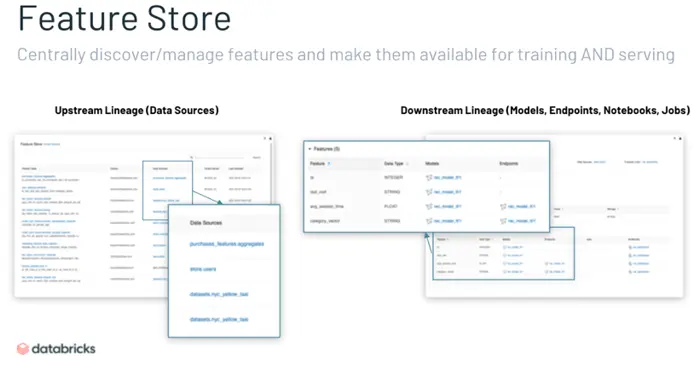
Basically, the feature store ensure developers and data scientists do not waste too much time on iterations and can be more productive by automating tasks and digital workflows. It optimizes time and elevates operational efficiency. The feature store paves the way to more efficient processes while ensuring that features are properly stored, documented, and tested.
Businesses have already started looking to bring great value for users by examining large amounts of data to uncover hidden patterns, correlations, insights and several new MLOps startups such as Arrikto and Comet.ml are developing leading-edge data science and ML technologies to methodically organize and manage data and bringing together data scientists to simplify, accelerate a secure model development. The key “benefits” are around “Automation”, “Time savings” and “Operational efficiencies” for all AI entrepreneurs and new-service (XaaS) pioneers alike!
SOURCES
- Your models need history and context. Get a Feature Store.
- Choosing a Feature Store: FEAST Vs Hopsworks
- How to build your own Feature Store
- Jim Dowling: The Sequence Chat
- 2021 – A year of ML Feature Stores Adoption
- Feature Store for ML
- Building a Gigascale ML Feature Store with Redis
- MLflow Guide – Azure Databricks
- Databricks Documentation
- Hottest Data Science and Machine Learning Startups 2021





