SharePoint 2013 Search Architecture and Components

Suneetha

Search architecture contains both search components and databases; building this search architecture is highly dependent on several factors, including high availability and fault tolerance, content available, estimated amount of page views and queries per second. Search in SharePoint 2013 comes with a fresh architecture and powerful components, categorized as a Feeding Chain, Search Core, Query Chain and Analytics Service (as detailed below).
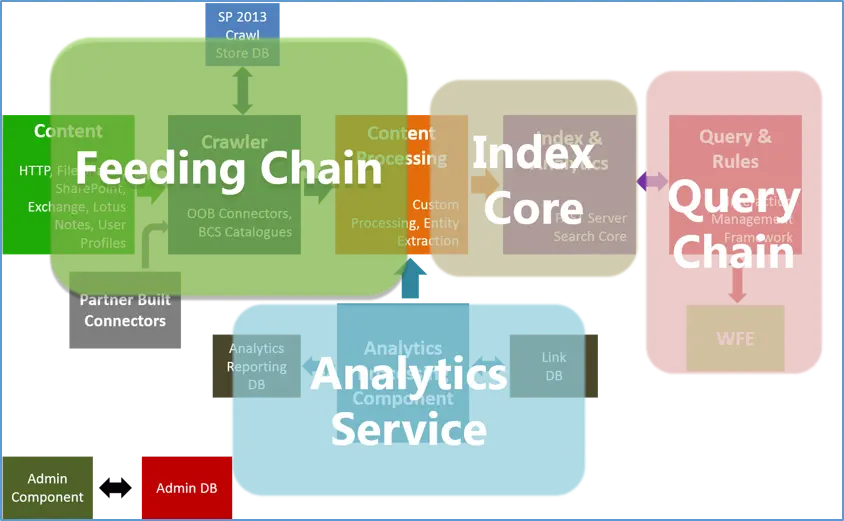
Search Architecture: Content Flow
What is the basic structure for Search in SharePoint 2013? We’ve broken it down here:

• MSSearch transfers responsibility to Host Controller Service
• MSSearch Process remains the Core Process for Crawl Component
• Independent NodeRunner processes for each component
SharePoint 2013 is split into six different components, all working together to provide an efficient, integrated experience. Let’s break down the six components here:
Search Administration Component: The search administration component runs the system processes for search, and performs provisioning – which adds and initializes instances of the other search components.
• Responsible for Topology Changes and provisions search
• Makes sure all components are up and running
• Uses Search Admin Database
• Sends schedule for Crawl Component and its content sources
Crawl Component: The crawl component crawls the content sources including file shares, SharePoint content, line of business applications and many more. Crawl component connects to the content sources, passing crawled items to the content processing component by invoking the appropriate indexing connector or protocol handler for retrieving information.
• Retrieves content that needs to be indexed
• Brings actual content and the metadata
• Invokes the protocol handlers
• Utilizes the Crawl Database to maintain list of items to be crawled
Content Process Component:
• Processes content from Crawler and Feeds to index
• New Parser Handler introduced Format Handler
• Writes links to link database
• Generates Phonetic Name Variations
• Content Submission Service – CSS
Analytics Processing Component:
The Analytics Processing Component performs search analytics and usage analytics to improve search relevance, create search reports, and generate recommendations and deep links. The results from the analyses are added to the items in the search index. Additionally, results from usage analytics are stored in the analytics reporting database.
• Uses Search Analytics to analyze Crawled Items, Executed Queries and clicked search results
• Generates Usage Reports of what’s been viewed, what sites have been visited, and how many times an item has been viewed
• Has the ability to add more APC Roles
• Data is stored in Analytics & Link DB
• Event store
Index Component
In the search topology, you have to provision one index component for each index replica; the Index Component receives processed items from the content processing component and writes those items to an index file. The component also receives queries from the query processing component and returns result sets.
• The spot where crawled data is placed
• Allows for Partial Data Update
• All index partitions are in sync
Query Processing Component
The Query Processing Component analyzes and processes queries and results to optimize precision, recall and relevance. It performs linguistics processing such as word breaking and stemming, and submits the query to the index component for further processing.
• Invoked when a query needs to be executed
• Analyzes and processes the query obtained from WFE
• Processed query is then sent to the index component
• Does initial linguistic processing (spell check, thesaurus, etc.)
• Transforms the query if the query rule matches





