The Role of Data Warehouses in AI and Modern Business Intelligence

Niranjan

What is a Data Warehouse?
A Data Warehouse is a central place where large amounts of data from different sources are stored. It is a database system used for data analysis and reporting, enabling better decision-making.
Characteristics of Data Warehouse
- Subject-Oriented: This is used to analyze a particular subject area.
- Integrated: This displays the integrated data from different sources
- Time variant: Historical data is usually maintained in a Data warehouse, i.e., we can retrieve the data of any period. In a transactional system, only the most recent data is maintained. However, in the Data warehouse, the transactional data is moved periodically, where both recent and previous data are also maintained.
- Non-Volatile: Once the data is placed in the data warehouse, it cannot be altered, which means we will never be able to change the historical data.
Need for Data Warehousing
In challenging times, good decision-making becomes critical. A data warehouse enhances the speed and efficiency of accessing large amounts of data, making it easier for corporate decision-makers to derive insights that guide business and decision-making strategies.
OLTP and OLAP
OLTP (Online Transaction Processing)
OLTP is essentially a database that stores daily transactions, also known as current data. Typically, OLTP is utilized in online applications that require frequent updates to maintain data consistency. OLTP deals with a relatively small amount of data.
OLAP (Online Analytical Processing)
OLAP is nothing but a Data Warehouse; OLAP is the study of data analysis for planning and decision-making. When it comes to aggregations, the data in OLAP will come from various sources. Compared to OLTP, OLAP handles large amounts of data.
| OLTP | OLAP |
| Keeps transactional data and has a small amount of data. | Stores historical data. It is a massive amount of data for users to inform business decisions. |
| Stores records of the last few days or weeks and has a fast response time. | High performance for analytical queries. |
| Uses ER Modelling techniques for Database design | Uses Dimension modelling techniques for Data Warehousing design. |
| Optimized for write operations (Insert, Update, and Delete) | Optimized for read operations. To access millions of records. |
| Tables and joins are complex since they are normalized. This is done to reduce redundant data and save storage space. | Tables & joins are simple since they are de-normalized. This is done to reduce the response time for analytical queries. |
Database and Data Warehousing
Database
A database is an organized collection of data, optimized for storing transactional activities, which allows users to easily access, manage, and retrieve data using a DBMS software. This can be treated as an OLTP system.
Data warehouse
A data warehouse is a centralized repository that stores and manages a large amount of data (historical data) from various sources, designed for analysis, reporting, and business intelligence (BI) purposes. This can be treated as an OLAP system.
| Database | Data Warehouse |
| A database is designed to store and manage data. | A data warehouse is designed to analyze data. |
| The database contains only a few records, i.e., current data. This data can be updated. | A data warehouse contains millions of records, i.e., Historical data. Here, this data cannot be updated. |
| The database has both read/write access. | The data warehouse has only read access. |
| A database is always normalized. | A data warehouse is denormalized. |
| The data view in the database will always be Relational. | The data view in the Data Warehouse is always Multidimensional. |
| The database contains detailed data. | A data warehouse contains the consolidated data. |
| Data in the Database needs to be available 24/7, meaning downtime is costly. | The Data Warehouse will not be affected by downtime. |
Data Mart
A Data Mart is a simplified form of Data Warehousing, focused on a single subject or line of business. A data mart is designed to serve the specific analytical needs of a particular department or business unit within an organization. Using Data Mart, the team can access data and gain insights faster because they don’t have to spend time searching within a complex Data Warehouse or manually aggregating data from different sources.
| Data Mart | Data Warehouse |
| A Data Mart stores Department data (a single subject) | A Data Warehouse stores enterprise data (Integration of multiple departments) |
| A Data Mart is designed for Middle Management. | A Data Warehouse designed for top management access. |
| The data warehouse size ranges from 100GB to 1TB. | Data Mart size is less than 100GB. |
| A Data Warehouse is focused on all departments of an organization. | Data Mart focuses on a specific group. |
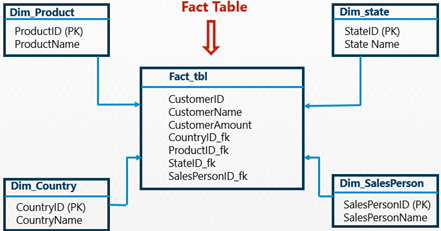
Dimension and Dimension Table
- Dimension is descriptive data that describes the key.
- The dimensions are organized in a table called the Dimension Table.
- Dimensional tables have Primary keys, which are related to foreign keys in the fact table.
- Dimension tables are de-normalized tables. It is also known as a Lookup table.
- There is no limit for dimensions in a Dimension Table. However, the Dimension table rows are relatively few compared to the fact table.
| Emp_ID | Emp_Name | City | Designation | Emp_Mobile |
| 101 | Santhosh | Chennai | Marketing | 94XXXXXX95 |
| 102 | Naresh | Hyderabad | Manager | 97XXXXXX53 |
| 103 | Brunda | Bangalore | Executive | 78XXXXXX28 |
| 104 | Srinivas | Hyderabad | Manager | 97XXXXXX52 |
| 105 | Mahesh | Mumbai | Accountant | 98XXXXXX43 |
Types of Dimensions
- Confirmed Dimension: A dimension that multiple fact tables can share.
- Junk Dimension: A dimension that can’t be used to describe facts in a fact table.
Fact & Fact Table
- Facts are numeric (Facts/Measures) in the Data Warehouse or Fact Table.
- A Fact table is a primary table in dimension modelling.
- A Fact table stores quantitative information for analysis & is often denormalized.
- A Fact table is the central table in a Star Schema of a Data Warehouse.
- A Fact table contains the foreign keys, which are primary keys in the Dimension Tables.
- The fact table contains a vast number of records.
| Date | Product_ID | Store_ID | Total_Sales | Profit | Average Sales |
| 2024-01-01 | P001 | S001 | 12,000 | 3,500 | 1,200 |
| 2024-01-01 | P002 | S001 | 8,500 | 2,000 | 850 |
| 2024-01-01 | P003 | S002 | 5,000 | 1,500 | 500 |
| 2024-01-02 | P001 | S001 | 15,000 | 4,200 | 1,500 |
| 2024-01-02 | P002 | S002 | 10,000 | 3,000 | 1,000 |
| 2024-01-02 | P003 | S003 | 6,500 | 1,700 | 650 |
| 2024-01-03 | P003 | S001 | 7,500 | 3,300 | 750 |
Types of Facts
- Additive Fact: An Additive fact is a fact that can be summed up through all the dimensions in the fact table.
In this, Sales_Amount is an Additive fact, because we can sum up this fact along with all three dimensions in the fact table.

- Semi-Additive Fact: In Semi-Additive Facts, facts can be summed up to some dimensions, not with others.

In this, Cur_Balance and Profit_Margin are facts. Cur_Balance is a Semi-Additive fact.
- Non-Additive Fact: Non-Additive facts that cannot be summed up for any of the dimensions present in the fact table.

In this, Profit_Margin is the Non-Additive Fact.
Dimensions and Facts Flow Diagram
Dimension Data Modeling Techniques
The dimension model in DWH arranges data in such a way that it is easier and faster to retrieve information and reports. The dimension model defines the Data modelling technique by defining the schema (Star and Snowflake schema).
Types of Schemas
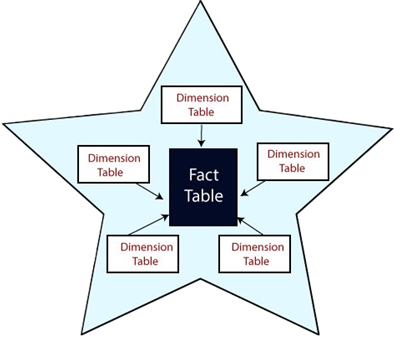
Star Schema: A Star Schema is a database that contains a centrally located fact table surrounded by multiple-dimensional tables. This looks like a STAR, so it is called Star Schema.
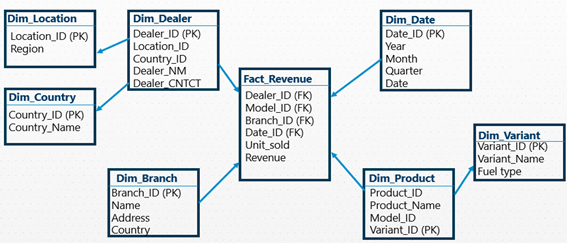
Snowflake Schema: Snowflake Schema is an extension of a STAR Schema where dimension tables are broken down into sub-dimensions. The dimension tables are normalized, which splits data into additional dimensional tables.
Testing fact and dimension tables involves several steps, i.e., data completeness, accuracy, and consistency, to ensure the proper functioning of foreign keys and relationships between the tables. Both types of tables are essential in a data warehouse, and ensuring their integrity and alignment with business rules is crucial for delivering reliable and accurate reports and analysis.
By following the steps outlined above, you can ensure that your fact and dimension tables are well-tested, perform optimally, and meet the business requirements of your data warehouse.
Normalization & De-Normalization
Normalization is the process of dividing data into multiple tables and establishing relationships among them. Normalization is used to remove redundant data from the database and store non-redundant, consistent data into it.
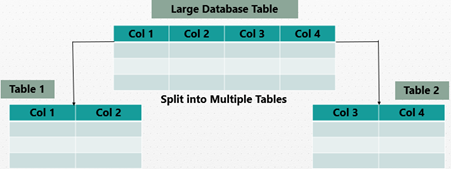
Denormalization is used to combine multiple tables of data into a single table, allowing for faster query processing.
SCD (Slowly Changing Dimension)
Slowly changing dimensions (SCD) determine how the historical data changes over time, rather than changing on a regular schedule, as time-based changes in the dimension tables are handled. Implementing the SCD mechanism enables users to know to which category an item belongs on any given date.
SCD Types
- SCD Type 1 (Overwriting of existing data)
- SCD Type 2 (Creates a new entry in the table)
- SCD Type 3 (Maintaining one-time history in new column)
For example, consider an employee named Athul who lives in Hyderabad. This can be represented in a table as below:
| ID | EmpID | EmpName | EmpDept | EmpCity | Year |
| 1 | 1001 | Athul | Dev | Hyderabad | 2023 |
SCD Type 1: This is used when there is no need to store historical data in the dimension table. In this, the old data is overwritten with the new data in the dimension table. No history is kept.
Ex: Athul is working in Hyderabad and gets transferred to Bangalore. The table will be changed as follows:
| ID | EmpID | EmpName | EmpDept | EmpCity | Year |
| 1 | 1001 | Athul | Dev | Bangalore | 2025 |
In this case, the previous entry, which is considered historical, is no longer available.
SCD Type 2: In this, both the original record and the new record inserted will be present in the same table. The new record gets its own primary key. It keeps all historical data. This is mainly for tracking the historical changes. The table will be changed as follows:
| ID | EmpID | EmpName | EmpDept | EmpCity | Year |
| 1 | 1001 | Athul | Dev | Hyderabad | 2023 |
| 2 | 1001 | Athul | Dev | Bangalore | 2025 |
SCD Type 3: In this, the previous record itself is always modified in such a way that neither the history is lost, nor is the newly inserted record displayed.
This can be achieved by creating two columns, one indicating a particular attribute of interest and the other indicating the current value, with the original value in the first column. There will also be a column that indicates when the current value becomes active. SCD Type 3 is rarely used. The table will be changed as follows:
| ID | EmpID | EmpName | EmpDept | Year | EmpCity (Old) | EmpCity (New) | Eff_Year |
| 1 | 1001 | Athul | Dev | 2023 | Hyderabad | Bangalore | 2025 |
Surrogate Key in the Data Warehouse
A Surrogate Key is a unique system-generated identifier (often an auto-incrementing integer) that uniquely identifies each row in a table. Surrogate key values have no commercial significance in the business-related data. These are mainly used in SCDs and for faster query performance.
| SURID | EmpID | EmpName | EmpCity | EmpRole |
| 1 | HOO1 | Ashok | Hyderabad | DEV |
| 2 | MOO2 | Raju | Mumbai | DEV |
| 3 | NOO3 | Ramu | Noida | QA |
| 4 | BOO4 | Srinivas | Bangalore | DEV |
| 5 | HOO1 | Ashok | Chennai | DEV |
| 6 | HOO1 | Ashok | Pune | DEV |
Testing in a Data Warehouse is essential to ensure the quality, reliability, and performance of the data and processes. Testing happens at different stages of the Data Warehouse lifecycle, including ETL processes, data validation, performance checks, security, and user acceptance. By thoroughly testing in these areas, you can ensure the data warehouse functions effectively and provides accurate, valuable insights.
1. ETL Testing (Extract, Transform, Load)
ETL processes move data from source systems to the data warehouse. Testing ensures the data is accurate and complete.
- Extraction Testing: Check if data is correctly extracted from the source systems (e.g., databases, APIs). Ensure missing or bad data is appropriately handled.
- Transformation Testing: Make sure business rules (like calculations) are applied correctly during transformation. Test for data consistency after transformation.
- Loading Testing: Verify data is loaded into the correct tables, like fact and dimension tables. Check that large datasets load correctly.
- Data Completeness and Consistency: Compare source data with the loaded data to ensure nothing is missing or duplicated.
2. Data Validation and Reconciliation Testing
Ensure that the data in the warehouse is accurate, valid, and matches the data in the source systems.
- Data Accuracy: Check that data in the warehouse matches the source system.
- Data Completeness: Ensure all records from the source are transferred to the warehouse.
- Data Consistency: Verify the data remains consistent over time. Reconcile totals or sums to match between systems.
3. Data Warehouse Schema Testing
This testing ensures the data warehouse schema (tables, views, relationships, etc.) is designed and functioning as expected.
- Table Structure Testing: Check that fact and dimension tables have the correct columns, data types, indexes, and keys. Verify relationships between fact tables and dimension tables (referential integrity).
- Data Modelling Validation: Make sure the data model (star or snowflake schema) is correct and meets business needs. Check that fact tables and dimension tables are correctly defined, normalized, and denormalized as needed.
4. Performance Testing
Test the performance of the data warehouse, particularly as the data volume grows and more users access it.
- Load Testing: Test how well the system handles large-scale data extraction, transformation, and loading without affecting the overall performance.
- Query Performance Testing: Check if queries, especially complex ones when working with large datasets, run quickly for OLAP.
- Scalability Testing: Test if the warehouse can handle more data or users.
- Stress Testing: Push the system to its limits to see how it performs under extreme conditions.
5. Data Governance and Security Testing
Ensure sensitive data is protected and access is controlled appropriately.
- Access Control Testing: Ensure that proper access permissions are implemented for various roles (e.g, read, write, admin) and that data is only accessible to authorized users. Verify that sensitive data is masked or encrypted as required.
- Data Privacy Testing: Ensure personal data or sensitive data is protected according to privacy regulations.
- Audit Trail Testing: Check if data access and modifications are logged with details like timestamps and user information.
6. Business Intelligence (BI) Reporting Testing
Test BI tools like Tableau or Power BI to ensure that reports and dashboards are accurate, complete, and function properly.
- Report Accuracy Testing: Verify reports match the data in the warehouse.
- Data Visualization Testing: Ensure charts and graphs display data correctly and meaningfully. Test interactive features, such as filters and drill-down options, to ensure they work correctly.
- User Interface (UI) Testing: Check if the BI tool’s interface is user-friendly and all buttons, filters, menus, and features work as expected.
7. Regression Testing
Make sure the new ETL processes and schema changes do not introduce new issues or break existing functionality.
- Test Existing Functionality: Re-run tests after changes to ensure everything still works.
- Test Data Integrity: Ensure that data integrity is maintained after updates.
8. User Acceptance Testing (UAT)
Test the data warehouse from the end user’s perspective to make sure it meets business requirements and is ready for deployment.
- Business Use Case Validation: Verify the system satisfies business requirements with sample queries and reports.
- Feedback Collection: Gather feedback from users to make sure the warehouse provides the necessary insights and data they need.
Conclusion
Testing within a Data Warehouse is not only a technical task but an essential process to guarantee the accuracy, reliability, security, and performance of data-oriented systems. Validating ETL processes and schema design, along with ensuring governance, scalability, and user satisfaction, comprehensive testing ensures that the data warehouse reliably provides accurate insights for business decisions. Through the adoption of organized and thorough testing at every phase, organizations can enhance the value of their data resources while reducing risks and mistakes.